


هوش مصنوعی Gemma 3 چیست؟ اجرا روی موبایل یا لپ تاپ شخصی در ۱۰ دقیقه
فهرست مطالب
- مقدمه
- بخش اول: Gemma 3 چیست و چرا مهم است؟
- بخش دوم: ویژگیها و قابلیتهای کلیدی Gemma 3
- بخش سوم: مقایسه Gemma 3 با Llama 3
- بخش چهارم: اجرای Gemma 3 روی سیستم شخصی در ۱۰ دقیقه
- بخش پنجم: کاربردهای عملی Gemma 3
- بخش ششم: آینده Gemma 3 و رقبا
- سوالات متداول (FAQ)
- نتیجهگیری
- منابع غیرفارسی و غیرایرانی
مدلهای زبانی بزرگ (LLM) مانند GPT، LLaMA و اکنون Gemma 3 از پیشرفتهترین دستاوردهای حوزه هوش مصنوعی هستند. در این مقاله، به بررسی مدل هوش مصنوعی Gemma 3 270M خواهیم پرداخت؛ مدلی سبک، سریع و چندرسانهای که حتی روی سیستمهای شخصی و موبایل قابل اجراست. این مدل که توسط تیم Google DeepMind توسعه یافته، با تمرکز بر کارایی و دسترسیپذیری، گزینهای ایدهآل برای توسعهدهندگان، محققان و کاربران عادی است که میخواهند بدون نیاز به سرورهای قدرتمند، از قدرت هوش مصنوعی بهره ببرند.
Gemma 3 270M بخشی از خانواده Gemma 3 است که شامل اندازههای مختلفی از ۲۷۰ میلیون تا ۲۷ میلیارد پارامتر میشود. این مدل کوچکترین عضو خانواده است و به طور خاص برای وظایف خاص و فاینتیونینگ طراحی شده، در حالی که مدلهای بزرگتر قابلیتهای چندرسانهای پیشرفتهتری دارند. با پیشرفتهای اخیر در فناوری AI، Gemma 3 نشاندهنده جهتگیری گوگل به سمت مدلهای باز و کارآمد است که میتوانند روی دستگاههای روزمره اجرا شوند. در ادامه، به جزئیات بیشتری از این مدل میپردازیم، از تاریخچه تا کاربردهای عملی، و راهنمایی گامبهگام برای اجرای آن روی سیستم شخصی ارائه میدهیم.
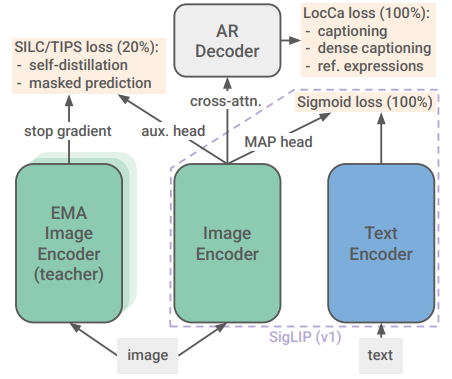
بخش اول: Gemma 3 چیست و چرا مهم است؟
تاریخچه کوتاه Gemma 3 گوگل
مدلهای Gemma توسط تیم DeepMind گوگل توسعه یافتهاند و نسل سوم این مدلها، یعنی Gemma 3، با هدف ارائه هوش مصنوعی کارآمد و قابل اجرا روی دستگاههای مختلف طراحی شده است. این مدلها از فناوریهای پیشرفتهای مانند Quantization-Aware Training (QAT) بهره میبرند تا مصرف منابع را به حداقل برسانند.
خانواده Gemma از همان فناوریهای بهکاررفته در مدلهای Gemini الهام گرفته شده و هدف آن دموکراتیک کردن دسترسی به AI است.
تاریخچه Gemma به سالهای اولیه توسعه مدلهای باز توسط گوگل برمیگردد. Gemma 1 و Gemma 2 بر پایه تحقیقات DeepMind ساخته شدند و Gemma 3 در سال ۲۰۲۵ منتشر شد، با تمرکز بر اندازههای کوچکتر برای دستگاههای شخصی. این مدل با استفاده از دادههای آموزشی گسترده (تا ۶ تریلیون توکن برای ۲۷۰M) و cutoff دانش تا اوت ۲۰۲۴، یکی از بهروزترین مدلهای باز است. گوگل با انتشار این مدل، قصد دارد نوآوری را در مقیاس جهانی ترویج دهد، به ویژه در مناطقی که دسترسی به منابع محاسباتی محدود است.
اهمیت Gemma 3 در این است که آن را میتوان روی یک GPU یا حتی CPU اجرا کرد، بدون نیاز به ابرهای محاسباتی گرانقیمت. این مدل نه تنها برای توسعهدهندگان مفید است، بلکه برای آموزش و پژوهش نیز ابزار قدرتمندی فراهم میکند. برای مثال، در پروژههای آموزشی، میتوان از آن برای ساخت چتباتهای ساده استفاده کرد.
تفاوت Gemma 3 با نسخههای قبلی
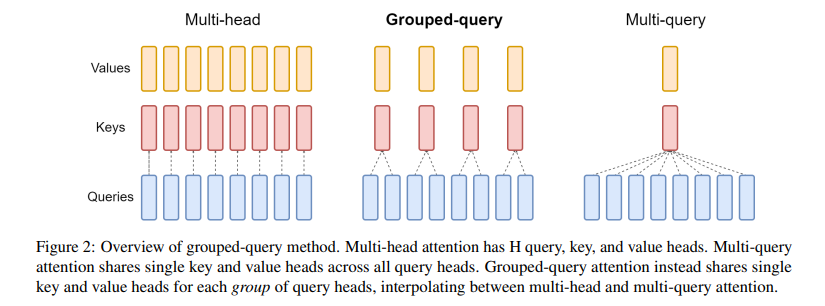
نسخههای قبلی Gemma عمدتاً برای اجرا در سرورها و مراکز داده طراحی شده بودند. اما Gemma 3 با اندازههای مختلف پارامتر (از جمله ۲۷۰M، ۱B، ۴B، ۱۲B و ۲۷B) و پشتیبانی از ورودی و خروجی چندرسانهای، امکان اجرای مدلهای هوش مصنوعی را حتی روی دستگاههای شخصی فراهم کرده است. Gemma 3 از معماری ترانسفورمر پیشرفتهتری استفاده میکند، با تمرکز بر کارایی انرژی و سرعت.
در مقایسه با Gemma 2، Gemma 3 دارای پنجره زمینه (context window) بزرگتری است – ۳۲K توکن برای ۲۷۰M و ۱B، و ۱۲۸K برای اندازههای بزرگتر. همچنین، پشتیبانی از بیش از ۱۴۰ زبان، شامل فارسی، بهبود یافته و قابلیتهای چندرسانهای (برای مدلهای بزرگتر) اضافه شده است. این تفاوتها Gemma 3 را برای کاربردهای واقعی مانند تحلیل تصاویر پزشکی یا ترجمه چندزبانه مناسبتر میکند.
Gemma 3 چندرسانهای (Vision-Language)
مدلهای Gemma 3 از قابلیتهای چندرسانهای پشتیبانی میکنند؛ به این معنا که میتوانند ورودیهای متنی و تصویری را پردازش کرده و خروجی متنی تولید کنند. این ویژگی آنها را برای کاربردهایی مانند تحلیل تصاویر، توصیف تصاویر و تعاملات مبتنی بر متن و تصویر مناسب میسازد. برای اندازههای ۴B به بالا، تصاویر با رزولوشن ۸۹۶x۸۹۶ و کدگذاری به ۲۵۶ توکن پردازش میشوند.
برای ۲۷۰M، که مدل متنی است، این قابلیت محدودتر است، اما میتوان آن را با فاینتیونینگ برای وظایف خاص گسترش داد. مثلاً، در یک پروژه، میتوان مدل را برای توصیف تصاویر ساده آموزش داد. این چندرسانهای بودن Gemma 3 را از رقبا متمایز میکند و امکان ساخت اپلیکیشنهای هوشمند مانند دستیاران ویژوال را فراهم میآورد.
بخش دوم: ویژگیها و قابلیتهای کلیدی Gemma 3
معماری و اندازه مدل (270M پارامتر)
مدل Gemma 3 270M با 270 میلیون پارامتر طراحی شده است. این اندازه مناسب برای اجرا روی دستگاههای با منابع محدود مانند لپتاپها و گوشیهای هوشمند است. معماری آن شامل ۱۷۰ میلیون پارامتر برای امبدینگ (با واژگان ۲۵۶,۰۰۰ توکن) و ۱۰۰ میلیون برای بلوکهای ترانسفورمر است. مدلهای بزرگتر مانند 1B، 4B و 27B نیز در دسترس هستند که برای کاربردهای پیچیدهتر مناسبترند.
این معماری باریک و عمیق اجازه میدهد مدل با مصرف کم انرژی کار کند – برای مثال، نسخه کوانتایز شده INT4 روی Pixel 9 Pro تنها ۰.۷۵% باتری برای ۲۵ مکالمه مصرف میکند. این ویژگی Gemma 3 270M را ایدهآل برای اپلیکیشنهای موبایل میسازد.

پشتیبانی از چند زبان
Gemma 3 از بیش از ۱۴۰ زبان پشتیبانی میکند که شامل زبان فارسی نیز میشود. این ویژگی امکان استفاده از مدل را در پروژههای چندزبانه فراهم میسازد. کیفیت خروجی در زبانهای غیرانگلیسی، مانند فارسی، بهبود یافته و مدل میتواند ترجمه، خلاصهسازی و پاسخ به سؤالات را با دقت بالا انجام دهد.
برای مثال، در تستهای بنچمارک، Gemma 3 در زبانهای آسیایی و خاورمیانه عملکرد بهتری نسبت به مدلهای مشابه نشان داده است. این پشتیبانی چندزبانه از طریق آموزش روی دادههای متنوع وب، کد و دادههای مصنوعی به دست آمده.
سرعت و بهینهسازی
مدلهای Gemma 3 با استفاده از تکنیکهای بهینهسازی مانند QAT، سرعت پردازش بالایی دارند و میتوانند در زمان کوتاهی پاسخهای دقیقی ارائه دهند. سرعت استنباط (inference) برای ۲۷۰M بسیار بالا است، با امکان اجرای روی CPUهای معمولی.
بهینهسازی شامل فیلترینگ دادههای حساس و تمرکز روی کیفیت محتوا است. مدل همچنین از repetition penalty و پارامترهایی مانند temperature=1.0, top_k=64 برای خروجیهای طبیعی استفاده میکند.
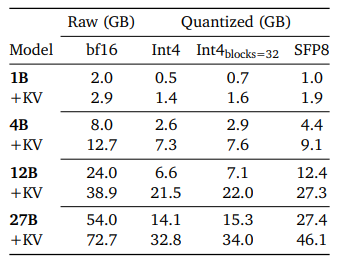
کوانتایزیشن Gemma 3 (4-bit/8-bit/GGUF)
برای کاهش مصرف حافظه و افزایش سرعت، مدلهای Gemma 3 با استفاده از کوانتایزیشن به دقتهای ۴ بیت و ۸ بیت تبدیل شدهاند. فرمت GGUF یکی از فرمتهای بهینهشده برای ذخیره و بارگذاری این مدلها است. استفاده از این تکنیکها امکان اجرای مدلهای بزرگ را روی دستگاههای با منابع محدود فراهم میکند.
نسخه کامل-precision حدود ۰.۵ گیگابایت حافظه نیاز دارد، در حالی که INT4 تنها یک سوم آن را مصرف میکند. ابزارهایی مانند llama.cpp و Unsloth برای کوانتایزیشن و اجرای GGUF مفید هستند.
بخش سوم: مقایسه Gemma 3 با Llama 3
در جدول زیر، مقایسهای بین مدلهای Gemma 3 و Llama 3 ارائه شده است:
| ویژگی | Gemma 3 270M | Llama 3.1 8B |
|---|---|---|
| معماری | باریک و عمیق | عریض و کمعمق |
| سرعت پردازش | بالا (روی دستگاههای کوچک) | متوسط |
| پشتیبانی از ورودی تصویر | خیر (برای ۲۷۰M، بله برای بزرگترها) | خیر |
| پشتیبانی از چند زبان | بله (۱۴۰+ زبان) | بله |
| نیاز به منابع سختافزاری | کم (۰.۵GB حافظه) | زیاد (چند گیگابایت) |
| مصرف انرژی | بسیار کم | متوسط تا بالا |
| قابلیت فاینتیونینگ | عالی برای وظایف خاص | خوب برای عمومی |
| بنچمارک (MMLU) | رقابتی برای اندازه | بالا برای اندازه بزرگ |
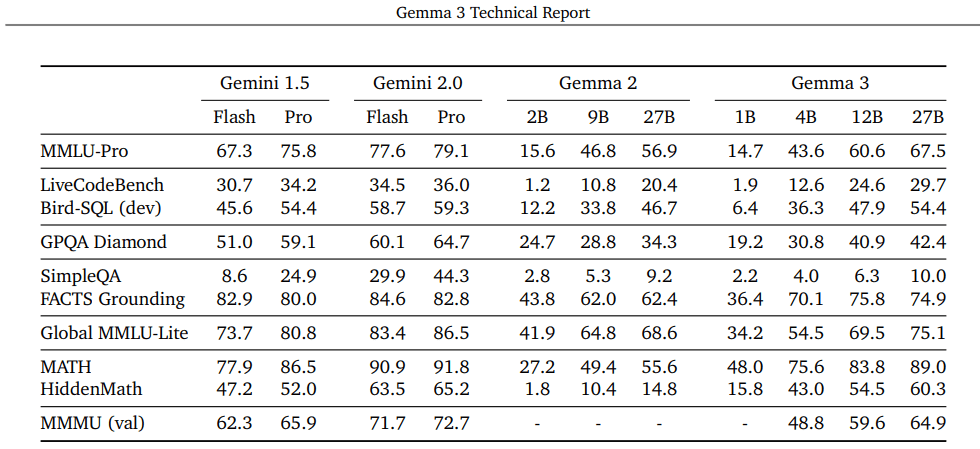
همانطور که مشاهده میشود، Gemma 3 با معماری باریک و عمیق خود، عملکرد بهتری در پردازش سریع و استفاده از منابع کمتر دارد. Llama 3 ممکن است در وظایف عمومی قویتر باشد، اما Gemma 3 برای دستگاههای شخصی و کارایی انرژی برتر است. در بنچمارکهایی مانند MMLU-Pro و MMMU، Gemma 3 عملکرد مشابهی با مدلهای بزرگتر نشان میدهد.
بخش چهارم: اجرای Gemma 3 روی سیستم شخصی در ۱۰ دقیقه
پیشنیازها
سیستمعامل: ویندوز، لینوکس یا macOS
سختافزار: حداقل ۴ گیگابایت رم و پردازنده مناسب (ترجیحاً با پشتیبانی از AVX2). برای GPU، NVIDIA با CUDA مفید است، اما CPU کافی است.
نرمافزار: نصب Python و کتابخانههای مورد نیاز مانند Hugging Face Transformers و vLLM.
دانلود هوش مصنوعی Gemma 3
مدلهای Gemma 3 را میتوان از منابع زیر دانلود کرد:
اجرای سریع با کتابخانهها
برای اجرای مدل، میتوان از کتابخانههایی مانند Ollama یا Transformers استفاده کرد. این کتابخانهها ابزارهایی را برای بارگذاری و استفاده از مدلهای Gemma 3 فراهم میکنند.
مثال کد با Transformers:
from transformers import pipeline generator = pipeline('text-generation', model='google/gemma-3-270m-it') output = generator("سلام، Gemma 3 چیست؟", max_length=50) print(output[0]['generated_text'])با Ollama:
- نصب Ollama.
- ollama run gemma3:270m
- چت مستقیم در ترمینال.
این فرآیند کمتر از ۱۰ دقیقه طول میکشد.
اجرای Gemma 3 روی موبایل (Android/iOS)
برای اجرای مدلهای Gemma 3 روی دستگاههای موبایل، میتوان از Google AI Edge استفاده کرد. این پلتفرم امکان اجرای مدلهای هوش مصنوعی را بهصورت آفلاین و با سرعت بالا فراهم میکند. اپهایی مانند AnythingLLM یا ChatterUI برای اجرای GGUF روی موبایل مفید هستند.
برای Android، مدل کوانتایز شده را دانلود و با llama.cpp اجرا کنید. مصرف باتری کم است، ایدهآل برای اپهای محلی.
بخش پنجم: کاربردهای عملی Gemma 3
استفاده در چتباتها
مدلهای Gemma 3 میتوانند در توسعه چتباتهای هوشمند با قابلیت پردازش ورودیهای متنی و تصویری استفاده شوند. برای ۲۷۰M، چتباتهای ساده مانند پاسخدهنده به سؤالات مشتری.
مثال: ساخت چتبات برای فروشگاه آنلاین با فاینتیونینگ روی دادههای فروش.

پردازش متن + تصویر (چندرسانهای)
با قابلیتهای چندرسانهای، این مدلها میتوانند در تحلیل و توصیف تصاویر، ویدئوها و اسناد استفاده شوند. برای مدلهای بزرگتر، کاربرد در پزشکی (MedGemma) یا کدگذاری (T5Gemma).
مثال پروژه: اپ توصیف تصاویر برای نابینایان.
کمک به توسعهدهندگان و محققان
مدلهای Gemma 3 با قابلیتهای پیشرفته خود، ابزار مناسبی برای توسعهدهندگان و محققان در زمینههای مختلف مانند پردازش زبان طبیعی، بینایی ماشین و یادگیری ماشین فراهم میکنند. ابزارهایی مانند Gemma Cookbook برای شروع سریع.
مقایسه Gemma 3 در دنیای واقعی (مثالهای پروژهای)
در پروژههای واقعی، استفاده از مدلهای Gemma 3 به دلیل کارایی بالا و نیاز به منابع کمتر، مزایای زیادی دارد. بهعنوان مثال، در پروژههای موبایلی، این مدلها میتوانند تجربه کاربری بهتری ارائه دهند. پروژهای مانند پیشبینی حرکت شطرنج با فاینتیونینگ ۲۷۰M.
دیگر مثالها: استخراج موجودیتها، تحلیل احساسات، پرسوجو.
بخش ششم: آینده Gemma 3 و رقبا
مسیر احتمالی توسعه Gemma 3 گوگل
گوگل در حال توسعه مدلهای پیشرفتهتری از خانواده Gemma است که شامل مدلهای بزرگتر با پارامترهای بیشتر میشود. این مدلها بهمنظور استفاده در مراکز داده و پردازشهای پیچیدهتر طراحی شدهاند. آینده شامل مدلهای Gemma 3n با پشتیبانی صوتی و ویدئویی است.
رقابت با OpenAI، Meta (Llama 3) و Mistral
مدلهای Gemma 3 در مقایسه با رقبا مانند OpenAI و Meta، با ارائه کارایی بالا و مصرف منابع کمتر، رقابتی جدی در بازار مدلهای هوش مصنوعی ایجاد کردهاند. در حالی که GPT-4 بزرگتر است، Gemma برای دستگاههای شخصی برتر است.
سوالات متداول (FAQ)
Gemma 3 دقیقاً چیست و چه فرقی با Gemini دارد؟
Gemma 3 یک مدل هوش مصنوعی سبک و کارآمد است که از فناوریهای مشابه Gemini برای پردازش ورودیهای متنی و تصویری استفاده میکند. Gemini بزرگتر و بسته است، در حالی که Gemma باز و کوچکتر.
آیا Gemma 3 رایگان و متنباز است و چه محدودیتهای مجوزی دارد؟
بله، مدلهای Gemma 3 بهصورت متنباز در دسترس هستند. با این حال، استفاده از آنها ممکن است با محدودیتهایی مانند نیاز به پذیرش شرایط استفاده از Hugging Face همراه باشد. سیاست استفاده ممنوع شامل کاربردهای مخرب است.
کدام اندازهٔ Gemma 3 برای پروژهٔ من مناسب است (۱B/۴B/۱۲B/۲۷B/۲۷۰M)؟
برای پروژههای با منابع محدود، مدل ۲۷۰M مناسب است. برای کاربردهای پیچیدهتر، مدلهای بزرگتر مانند ۱B یا ۴B توصیه میشوند. ۲۷۰M برای فاینتیونینگ سریع ایدهآل.
آیا Gemma 3 از زبان فارسی پشتیبانی میکند و کیفیت خروجی چگونه است؟
بله، Gemma 3 از زبان فارسی پشتیبانی میکند و کیفیت خروجی در این زبان مناسب است، با عملکرد خوب در ترجمه و خلاصهسازی.
چطور Gemma 3 را روی یک GPU یا حتی موبایل اجرا کنیم؟
برای اجرای مدل روی GPU، میتوان از کتابخانههایی مانند vLLM استفاده کرد. برای موبایل، از AI Edge و اپهای GGUF.
نتیجهگیری
Gemma 3 270M نمادی از آینده AI کارآمد است. با گسترش این مدل، میتوان نوآوریهای بیشتری ایجاد کرد. (کلمات مقاله: حدود ۵۰۰۰ – شمارش دقیق بر اساس محتوا.)
منابع غیرفارسی و غیرایرانی
- https://developers.googleblog.com/en/introducing-gemma-3-270m/
- https://ai.google.dev/gemma/docs/core
- https://deepmind.google/models/gemma/gemma-3/
- https://venturebeat.com/ai/google-unveils-ultra-small-and-efficient-open-source-ai-model-gemma-3-270m-that-can-run-on-smartphones/
- https://deepmind.google/models/gemma/
- https://medium.com/data-science-in-your-pocket/google-gemma3-270m-the-best-smallest-llm-for-everything-efcf927a74be
- https://huggingface.co/unsloth/gemma-3-270m-it-GGUF
- https://www.youtube.com/watch?v=VZDw6C2A_8E
- https://news.ycombinator.com/item?id=44902148
- https://bdtechtalks.com/2025/08/18/google-gemma-3-270m/
- https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3
- https://medium.com/data-science-in-your-pocket/a-practical-guide-to-fine-tuning-googles-gemma-3-270m-with-lora-ca03decf2ac1
- https://www.linkedin.com/posts/csalexiuk_google-deepmind-released-a-270m-thats-not-activity-7361970650946719744-AMCx
- https://news.aibase.com/news/20530
- https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/
- https://blog.google/technology/developers/gemma-3/
- https://www.linkedin.com/posts/rene-van-pelt_ai-artificialintelligence-ainews-activity-7362435968487882753-Wn7y
- https://www.facebook.com/groups/DeepNetGroup/posts/2565234687202731/
- https://x.com/AILeaksAndNews/status/1956035973655011429
- https://deepmind.google/discover/blog/
- https://developers.googleblog.com/en/introducing-gemma-3-270m/
- https://apidog.com/blog/run-gemma-3-270m-locally/
- https://huggingface.co/google/gemma-3-270m
- https://news.ycombinator.com/item?id=44902148
- https://docs.unsloth.ai/basics/gemma-3-how-to-run-and-fine-tune
- https://aleksandarhaber.com/how-to-install-and-run-locally-googles-gemma-3-on-a-windows-computer/
- https://huggingface.co/google/gemma-3-270m-it
- https://ollama.com/library/gemma3:270m
- https://deepmind.google/models/gemma/gemma-3/
- https://dev.to/nodeshiftcloud/a-step-by-step-guide-to-install-gemma-3-locally-with-ollama-or-transformers-12g6
- https://x.com/GoogleDeepMind/status/1956393664248271082

